Neural Networks, Brain Bugs and Deep Learning
By Gunnar Schulze
20.06.2016
The human brain is an amazing machine. Continuously, and often unconsciously, it interprets the world around us through a rich set of senses. Our eyes see, our lips taste, our ears hear, our nose smells. And proprioreception gives us a subtle understanding of movement and gravity. But the physical ‘front end’ is only the start. Even more importantly, our brain can integrate all these signals, it can extract patterns, it can learn, it can predict. And it can update beliefs if these do not fit the outside world anymore (although some would prefer it the other way round).
To do that our brain uses millions of specialized cells, called neurons, each receiving its very own input and output signals and integrates them through a complex configuration of connections, called synapses (Figure 1). Without a doubt, few things in life sciences are as fascinating and yet still remain as elusive as this machinery. For decades now, and probably decades to come, neuroscientists have been digging into this complex system, exploring the depths of the human mind. Their research is important not only to better understand the molecular mechanisms that enable us to perceive the world as we do, but also to develop means to prevent, treat and one day eventually cure the large spectrum of neurodegenerative diseases we observe today. From a biological perspective the (human) brain offers a sheer endless source of both powerful insights and puzzling challenges.
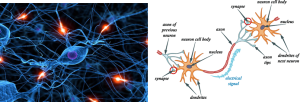
Figure 1: Neurons connected through synapses form a neural network. (image sources: extremetech.com, blog.bufferapp.com)
And yet neuroscientists are not the only researchers interested in the brain. In the early 1980’s, computer scientists found a way to extract the abstract principles behind the organization of neural networks and formulated them in a way that can be represented in terms of computer programs. The grand vision underlying these efforts is that of ‘artificial intelligence’ – to design and engineer truly intelligent artificial systems that not only perform well in preprogrammed tasks and controlled settings but are actually capable of adapting and ‘learning’ in completely new circumstances. Even if that still sounds pretty much like science fiction à la Hollywood, there are actually some immediate, real world problems, artificial neural networks (ANNs) can help with. The perhaps biggest category of such problems are the so called ‘machine learning’ or ‘classification’ problems. What is that?
Classification problems arise in many situations both in science and in our everyday life. In (life-) science we often ask questions like: “Which of these observations are similar (i.e. belong to a group), based on this or that measure?” Or: “Given our previous observations and corresponding measurements, to which group belongs this new observation?” In fact, categorizing things seems to be a major feature of human thinking and we can easily come up with more practical applications.
For example, to maximize our daily ‘feel-good’ time, we might want to group people around us according to whether we like them (friends perhaps) or not, based on certain features we deem pleasant or repelling and avoid running into the second kind all too often. If we encounter a new person, we, or rather our subconscious mind, makes a prediction as to whether we could come to like that person or not (which apparently takes us just 7 seconds*). Many factors can be involved in this process, but certainly personal experience with other people is one of them. *http://www.dailymail.co.uk/femail/article-1338064/Youve-got-7-seconds-impress-How-size-men-time.html
Whatever your opinion on stereotypes is (probably there are more than two categories for people)- these two examples nicely describe the two typical flavors of machine learning, which are usually described as ‘unsupervised’ and ‘supervised’ learning. Well-formulated methods and specifically tailored algorithmic solutions have been developed and successfully applied for each of these problems.
Our brain, however, is obviously capable of solving both supervised and unsupervised problems within the same internal structure and so an intriguing question is whether computer science, too, could employ a single approach to solve both problems in one go. And that is just what happens to be the big charm of artificial neural networks (ANNs).
When training a neural network for classification, we feed it with input data in a very raw state and let it determine the important features on its own. In machine learning jargon this type of learning is often called ‘representation learning’, because our classifier learns a different way to represent the data and its inherent information.
With regard to our little toy example (Figure 2), this corresponds to the case when our brain collects a lot of data on people’s behaviour and tries to figure out whom we might get along well with (or not). It takes a bunch of input characteristics, e.g. ‘smiling’ or ‘chatty’ behaviour and constructs patterns that work together on higher levels of abstraction to predict some measure of ‘niceness’ of a person. Usually we are not being told to like someone or what patterns we should look out for – it is a matter of complex calculations and often subconscious decisions our brain takes ‘for us’. It feels like a very natural, ‘learning-by-doing’ way of training a classifier. At the same time, however, it is hard to imagine a ‘machine’ or computer to carry out such an almost random looking learning task and then to come up with good predictions we can actually use. It looks much like the often quoted ‘black-box’ (bio)informatics, many researchers remain sceptical about.
So let’s take a look under the hood. How do you get a brain into a computer?
In mathematical or computer science terms, a neural network can be best understood using an abstract structure called “graph”. In their simplest form, graphs consist of nodes (or units in neural networks) and connections between these nodes, called edges. Transferring that to the structures of a brain, you can think of nodes as representations of individual neurons and edges as representations of the synapses connecting them (Figure 2). Each edge between two nodes has an associated parameter that determines how a signal is propagated by one node to the next. If you know your neurobiology, you might want to think of these parameters as the strength of individual synapses (e.g. the amount of signalling molecules that are transmitted) as well as their effect on the propagated signal, which encodes the difference between excitatory and inhibitory synapses. The nodes serve as integrators and convert all incoming signals into a single value that is called the “activation” of that unit.
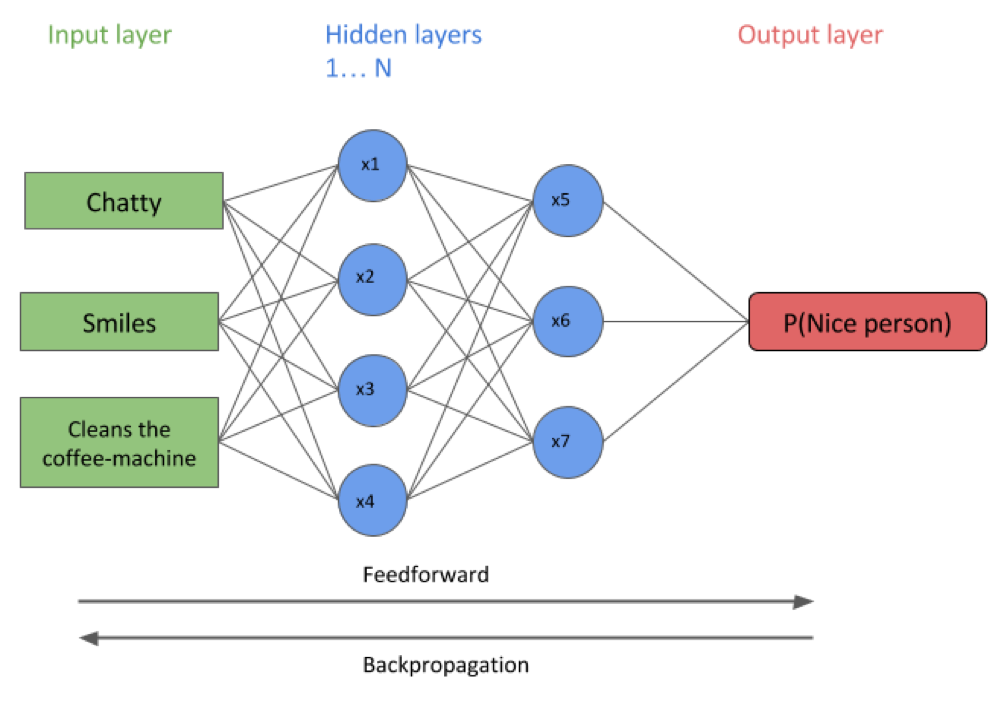
Figure 2: A toy example for an artificial neural network that predicts the probability that we might like a person based on some characteristic features (arbitrarily chosen).
How do we get a neural network to predict things?
The fundamental step in applying artificial neural networks is the learning/training procedure. It is a two-step process in which first the input data (or layer) generates an output in each node of the first hidden layer. This signal then proceeds through the different hidden layers of the network in a feedforward mechanism through which it is integrated with other signals until it (finally) reaches the output level. This stage is usually called ‘forward propagation’. The predictions derived from the neural network are compared with the expected (known) observations and the error made by the network in its current state is quantified. The goal is obviously to minimize this error or in other words to force the network into another state where it comes up with more accurate predictions. To do that, we can look at how the overall error was generated through each layer of the network and adjust the associated parameters accordingly. Since we are now going backwards (from output to input) this procedure is commonly referred to as “backward propagation of errors” or simply “backpropagation”. But here is a problem: We cannot enumerate all possible combinations of parameters and evaluate which is the best set – there are just too many! Instead, usually an algorithm called “gradient descent” is employed that is often used to find optimal parameters in regression and logistic regression problems. Finally, the entire process of forward- and backpropagation is repeated a number of times until the network produces a sensible output or a predefined number of training iterations is reached. Et voilà – that’s neural network training!
Now that we have a neural network and have a basic idea how it can be trained – what can we use it for?
As mentioned earlier, ANNs are not a new thing and the fundamental methods were already developed in the 1980s when computer scientists realized their potential for applications such as visual and speech recognition as well as ‘scene understanding’ – the interpretation of an image containing several objects in a specific context[1]. These methods are also the top candidates for autonomous driving, self-organizing robots and many more. In principle, the applications are endless.
So what has taken these methods so long to find their way into the data analyst’s suitcase?
First of all, the popularity of ANNs suffered severely from one of the most common problems in machine learning, called ‘overfitting’. This happens when we train and adjust our machines or ‘classifiers’ too well for a particular purpose or input data and then discover that we can’t apply it in the same way to a similar, but also slightly different problem or dataset. Thinking of our ‘persons-to-like’ problem again, we might discover that if we travel to another country we should actually update our beliefs to not be trapped within (false) stereotypes. Overfitting is especially a problem with complex, multi-layered networks, with many units that together generate a huge parameter space that can be highly optimised for a particular dataset. After adapting already known methods like ‘regularization’ or the use of ‘latent classes’ for neural networks these issues could however eventually be addressed. An additional, more technical challenge was the high computational complexity of finding the optimal parameters for big neural networks which seemed infeasible even with clever algorithms. Initially, methods like pre-training networks on smaller inputs, followed by thorough optimization on the entire data were invented to address this challenge. Finally, when GPU-aided computing became more and more common, both networks and input datasets were allowed to grow even further, overcoming previous limitations.
Perhaps not very surprisingly, due to their powerful and versatile application, (deep) neural networks are nowadays part of almost every smartphone’s speech recognition or text completion software, customer-recommendation systems, social media and many more.. Likewise, since the rediscovery of neural networks for bioinformatic purposes, initiatives and companies such as Deep Genomics http://www.deepgenomics.com/ drive the progress of deep learning applications in biological and biomedical research.
In 2012, the outcome of the DREAM5 challenge marked such a major breakthrough when a deep neural network classifier called deepBind[2] outperformed all competing state-of-the-art methods in reconstructing gene regulatory networks from gene expression data.
Given these advances and the possibility to apply ANNs to basically any kind of input data, we can expect that deep learning methods will become more and more important and will soon belong also to the standard toolkit in sequence pattern analysis, genetic variant annotation, drug discovery and deconvolution of gene regulatory networks. Beyond generating powerful classifiers, the hope is further that, by looking at the internal layers of trained neural networks, we might be able to better understand some of the deeper principles of how things work in nature.
An interesting analogy to the human brain might, however, bring in another challenge: When repeatedly training the same network on different input datasets, it has been observed that useful properties can be lost or „forgotten“. Scientists have therefore proposed the introduction of so called „memory cells“ – specialized nodes in the network that have self-connections and reinforce their own functionality even after repeated training. Thus, whether you will actively apply neural networks in your research or just use them to ask “Siri” to call Dr. Rajesh Koothrappali – every once in a while it is good to take a look behind the curtain and ensure we are not suffering from all too many bugs in our powerful new artificial brains.
References
[1] Deep learning. Yann LeCun, Yoshua Bengio & Geoffrey Hinton. Nature Reviews, May 2015
[2] Predicting the sequence specificities of DNA- and RNA-binding proteins by deep learning. Babak Alipanahi, Andrew Delong, Matthew T Weirauch & Brendan J Frey. Nature Computational Biology, August 2015
Post scriptum:
Applications and methods based on neural networks come in many flavors and are simply impossible to cover entirely in just one article, let alone a blog post. If you, dear reader, feel inspired and want to know more about this exciting topic I can highly recommend you to check out the references listed above as well as some additional resources linked below.
Additional resources:
- Machine learning course on coursera (covering neural networks): https://www.coursera.org/learn/machine-learning/
- Tryout a neural network interactively using the Deep playground App: http://playground.tensorflow.org
- More on artificial intelligence in computer science: http://artint.info/html/ArtInt_183.html